Factor Analysis is a technique of expressing observed variables in the form of potentially lower number of latent variables called factors. In a given dataset, highly correlated variables can be grouped into factors which helps in reducing the number of variables to work with, which is called as reducing the dimensionality.
When dealing with large datasets, factor analysis can be used to group several variables into few categories which focus on key components of each variable.
There are 2 important decisions to make when using factor analysis on data:
Mathematics Lens:
Factor analysis finds the location of the axes that fits the data better by rotating the axes. The rotation makes the factors more understandable. Rotations can be orthogonal or oblique.
Orthogonal Rotation:
Orthogonal rotation does not allow the factors to be correlated by always restricting the angle between the axes to 90 degrees. Varimax, Equimax, Quartimax are the types of Orthogonal rotation.
The Blue lines indicate the new x and y-axes after orthogonal transformation
Oblique Rotation:
Oblique rotation allows the factors to be correlated by allowing the angle between the axes to be less than 90 degrees. Direct Oblimin, Promax methods use Oblique rotation for factor analysis.
The Blue lines indicate the new x and y-axes after applying Oblique rotation
Consider the following dataset of rating given to each subject by 300 students.
Have a look at the first 10 rows.

In R, the correlation matrix can be generated by `cor()` command.
corMat = cor(my.data)Output:

From the above table, we can infer the following:
Factor Analysis with No Rotation:
n.factors = 3
fit = factanal(my.data, n.factors, rotation="none", scores="regression")
fit
#Check Loadings
fit$loadings
load = fit$loadings[,]
load
Takeaways from the above output:
Eigenvalue is a good indicator to confirm how many factors to use. The scree plot can be used to plot the eigenvalues of the factors involved, it shows the number of factors on x-axis and eigenvalues on y-axis.
scree.plot(fit$correlation)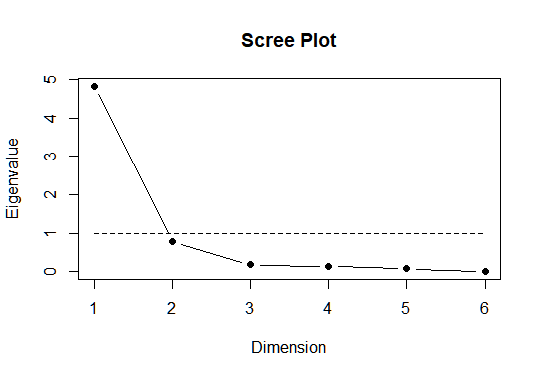
Factor Analysis with Orthogonal Rotation - Varimax:
n.factors = 2
fit = factanal(my.data, n.factors, rotation="varimax", scores="regression")
load = fit$loadings[,]
load
scree.plot(fit$correlation)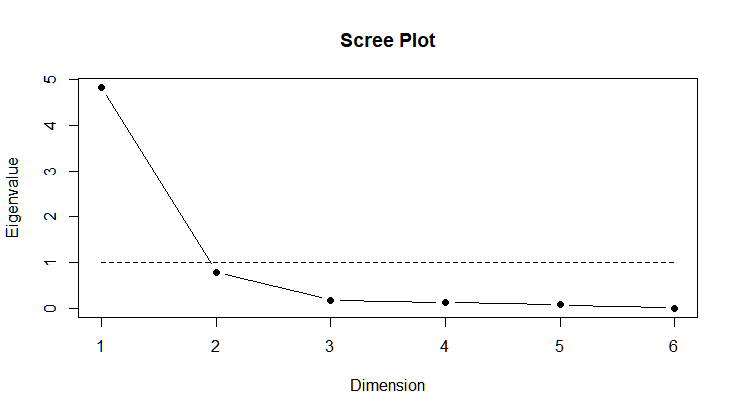
NOTE:
“None”, “Varimax” are both orthogonal rotations.
n.factors = 2
fit = factanal(my.data, n.factors, rotation="oblimin", scores="regression")
load = fit$loadings[,]
loadOutput:

scree.plot(fit$correlation)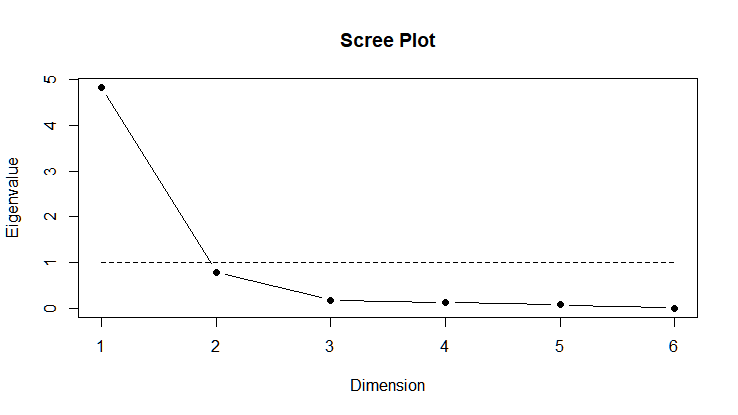
Business Lens:
Factor Analysis is widely used in psychological research and assessment scales like customer satisfaction, perceptions which cannot be measured directly. Initially, the customer/subject is provided with large set of questions which are usually answered on a numeric scale like 1-10. Then the psychological state can be indirectly measured based on the responses provided by the subject.
Let’s look at a business problem of a Tooth paste brand which wants to get an insight on customers’ behavioral pattern to price and promote their product accordingly.
Here is the sample data from the survey:

The correlations between the above features are as follows:
corMat = cor(myData)
corMat
A negative correlation between 2 variables indicates that when one variable increases, the other decreases and vice versa. Generally, anything above 0.7 can be considered a good correlation. As we can see in the above table, there is a correlation between the variables, hence, factor analysis can be performed on the data.
n.factors = 2
fit = factanal(myData, n.factors, rotation="oblimin", scores="regression")
loadings = fit$loadings[,]
loadingsOutput:

scree.plot(fit$correlation)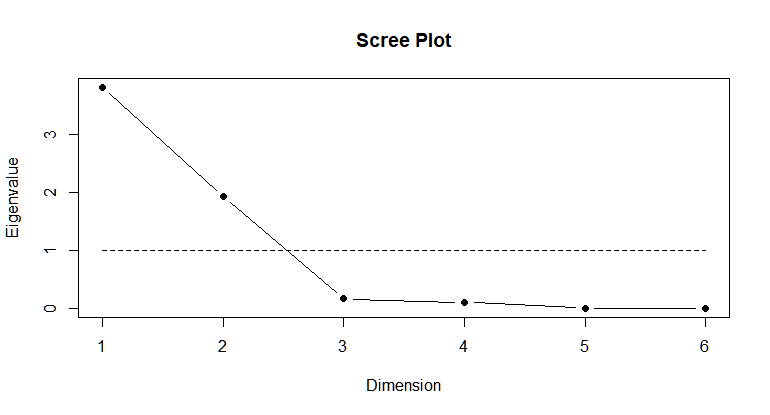
From the above analysis, the participants in the survey can be categorised into 2 groups, one that prioritizes health of their teeth and the other group that prefers visual appearance of their teeth. Based on this, the company can take a decision to promote their toothpaste brand to appeal to the either of the group or they can manufacture separate products for each group of people. Another interesting observation is that price is highly and inversely correlated with PreCavity and StrongGum which can be an indication that people prefering health of their teeth are not much bothered about the price of the product. Thus, the company can also plan the pricing of their product from this analysis.





