Data science is a multidisciplinary field which requires knowledge of math, technology and domain.
Based on the business requirements, the analysis needed are:
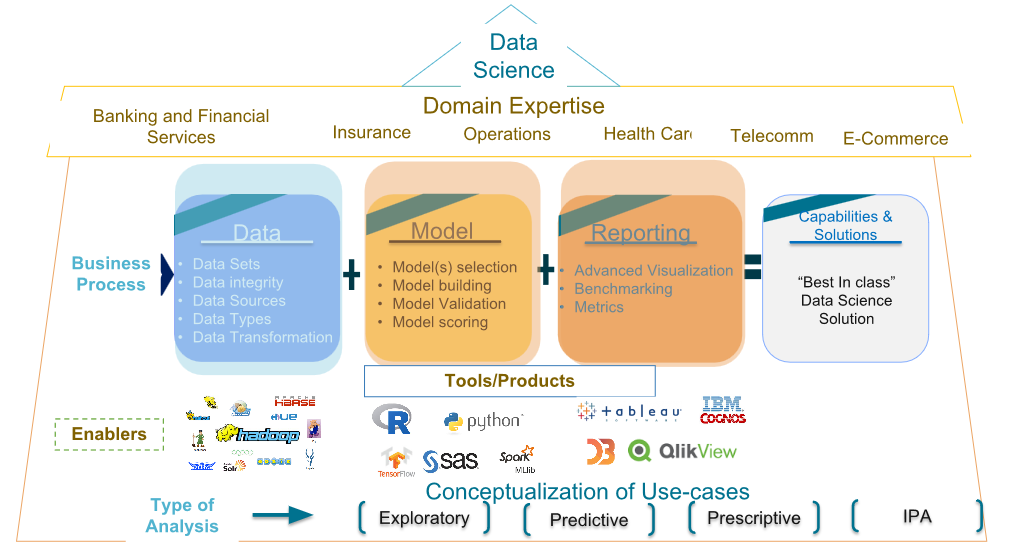
Tools/Products
Data Science Lifecycle
Business Requirement
The first step is to define the objective by discussing with customers or stakeholders to identify the business problems and define the target metric for the project.
Collecting the data
The next step is to acquire the relevant data by direct sources like analytics or from third party sources if necessary. High quality data is an important requirement of a data science project.
Understanding the data
Before training a model, it is important to explore the data first. Most of the data in production has missing values and errors, they should be dealt with domain knowledge and available algorithms. The data may also be normalized and transformed for better model training.
Creating a model
Out of all the columns available in the dataset, choosing the relevant columns is an important task, this is called feature engineering. It needs exploration of data and domain expertise to decide on the features to use for training the model.
Based on the problem statement of the project, there are different types of models available to choose. The models can be compared with each other by metrics like accuracy.
The model creation includes the following steps:
Deploying the model
Decide whether the accuracy of the model is sufficient to use in production. If not, try training the data on different models and collect more data if necessary. Once the model is finalized, deploy the model to web to facilitate users to get predictions using their data. APIs can be used to get predictions from other applications as well.





