Article Information
- Posted By : Rakesh Racharla
- Posted On : Jul 15, 2020
- Views : 1218
- Category : Predictive and Prescriptive Modeling » Machine Learning
- Description : Generative modeling is an unsupervised learning task in machine learning that involves automatically discovering and learning the regularities or patterns in input data in such a way that the model can be used to generate or output new examples that plausibly could have been drawn from the original dataset.
Overview
Generative modeling is an unsupervised learning task in machine learning that involves automatically discovering and learning the regularities or patterns in input data in such a way that the model can be used to generate or output new examples that plausibly could have been drawn from the original dataset.
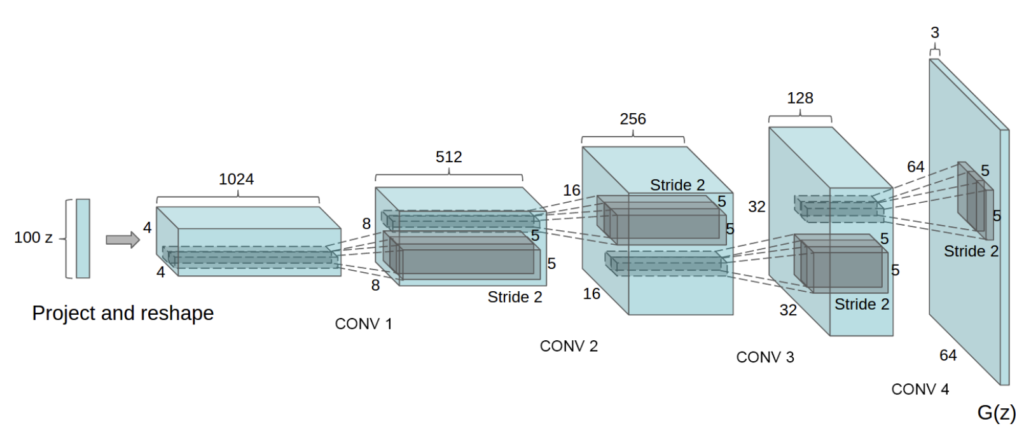
DCGAN is one of the most popular and successful network design for GAN. It mainly composes of convolution layers without max pooling or fully connected layers. It uses convolutional stride and transposed convolution for the downsampling and upsampling.
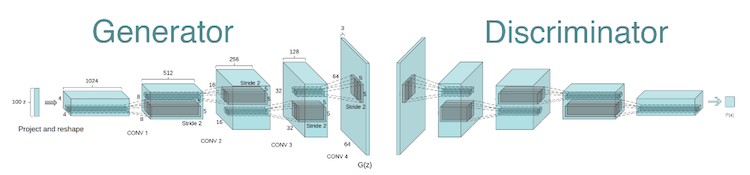
Source: https://medium.com/sigmoid/a-brief-introduction-to-gans-and-how-to-code-them-2620ee465c30The GAN model architecture involves two sub-models: a generator model for generating new examples and a discriminator model for classifying whether generated examples are real, from the domain, or fake, generated by the generator model.
Generator Model that is used to generate new plausible examples from the problem domain.
Discriminator Model that is used to classify examples as real (from the domain) or fake (generated).
- The Generator Model.
The generator model takes a fixed-length random vector as input and generates a sample in the domain.
Source:https://machinelearningmastery.com/how-to-train-stable-generative-adversarial-networks/The vector is drawn randomly from a Gaussian distribution, and the vector is used to seed the generative process
The Discriminator Model.
The discriminator model takes an example from the domain as input (real or generated) and predicts a binary class label of real or fake (generated).

Source:https://www.oreilly.com/ideas/deep-convolutional-generative-adversarial-networks-with-tensorflow
The real example comes from the training dataset. The generated examples are output by the generator model.
The discriminator is a normal (and well understood) classification model.
The Structure of Generative Adversarial Network is represented as follows:
Source:https://sigmoidal.io/beginners-review-of-gan-architectures/
Here we train a DCGAN model to Generate Faces.
Here is the code below:
First, we import all the required libraries.
from keras.layers import Input, Reshape, Dropout, Dense, Flatten, BatchNormalization, Activation, ZeroPadding2D from keras.layers.advanced_activations import LeakyReLU from keras.layers.convolutional import UpSampling2D, Conv2D from keras.models import Sequential, Model, load_model from keras.optimizers import Adam import numpy as np from PIL import Image from tqdm import tqdm import osThe source data (faces) used in this module can be found here:
Pre-processing the data:
# Generation resolution - Must be square # Training data is also scaled to this. # Note GENERATE_RES higher than 4 will blow Google CoLab's memory. GENERATE_RES = 2 # (1=32, 2=64, 3=96, etc.) GENERATE_SQUARE = 32 * GENERATE_RES # rows/cols (should be square) IMAGE_CHANNELS = 3 # Preview image PREVIEW_ROWS = 4 PREVIEW_COLS = 7 PREVIEW_MARGIN = 16 SAVE_FREQ = 100 # Size vector to generate images from SEED_SIZE = 100 # Configuration DATA_PATH = '/content/drive/My Drive/Colab Notebooks/GANs/Face Generation DCGAN/' EPOCHS = 10000 BATCH_SIZE = 32 print(f"Will generate {GENERATE_SQUARE}px square images.")Loading the Data:
# Image set has 11,682 images. Can take over an hour for initial preprocessing. # Because of this time needed, save a Numpy preprocessed file. # Note, that file is large enough to cause problems for sume verisons of Pickle, # so Numpy binary files are used. training_binary_path = os.path.join(DATA_PATH,f'training_data_{GENERATE_SQUARE}_{GENERATE_SQUARE}.npy') print(f"Looking for file: {training_binary_path}") if not os.path.isfile(training_binary_path): print("Loading training images...") training_data = [] faces_path = os.path.join(DATA_PATH,'face_images') for filename in tqdm(os.listdir(faces_path)): path = os.path.join(faces_path,filename) image = Image.open(path).resize((GENERATE_SQUARE,GENERATE_SQUARE),Image.ANTIALIAS) training_data.append(np.asarray(image)) training_data = np.reshape(training_data,(-1,GENERATE_SQUARE,GENERATE_SQUARE,IMAGE_CHANNELS)) training_data = training_data / 127.5 - 1. print("Saving training image binary...") np.save(training_binary_path,training_data) else: print("Loading previous training pickle...") training_data = np.load(training_binary_path)Define the Generator Model:
def build_generator(seed_size, channels): model = Sequential() model.add(Dense(4*4*256,activation="relu",input_dim=seed_size)) model.add(Reshape((4,4,256))) model.add(UpSampling2D()) model.add(Conv2D(256,kernel_size=3,padding="same")) model.add(BatchNormalization(momentum=0.8)) model.add(Activation("relu")) model.add(UpSampling2D()) model.add(Conv2D(256,kernel_size=3,padding="same")) model.add(BatchNormalization(momentum=0.8)) model.add(Activation("relu")) # Output resolution, additional upsampling for i in range(GENERATE_RES): model.add(UpSampling2D()) model.add(Conv2D(128,kernel_size=3,padding="same")) model.add(BatchNormalization(momentum=0.8)) model.add(Activation("relu")) # Final CNN layer model.add(Conv2D(channels,kernel_size=3,padding="same")) model.add(Activation("tanh")) input = Input(shape=(seed_size,)) generated_image = model(input) return Model(input,generated_image)Define the Discriminator Model:
def build_discriminator(image_shape): model = Sequential() model.add(Conv2D(32, kernel_size=3, strides=2, input_shape=image_shape, padding="same")) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.25)) model.add(Conv2D(64, kernel_size=3, strides=2, padding="same")) model.add(ZeroPadding2D(padding=((0,1),(0,1)))) model.add(BatchNormalization(momentum=0.8)) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.25)) model.add(Conv2D(128, kernel_size=3, strides=2, padding="same")) model.add(BatchNormalization(momentum=0.8)) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.25)) model.add(Conv2D(256, kernel_size=3, strides=1, padding="same")) model.add(BatchNormalization(momentum=0.8)) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.25)) model.add(Conv2D(512, kernel_size=3, strides=1, padding="same")) model.add(BatchNormalization(momentum=0.8)) model.add(LeakyReLU(alpha=0.2)) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) input_image = Input(shape=image_shape) validity = model(input_image) return Model(input_image, validity)Defining a function to save the Generated images:
def save_images(cnt,noise): image_array = np.full(( PREVIEW_MARGIN + (PREVIEW_ROWS * (GENERATE_SQUARE+PREVIEW_MARGIN)), PREVIEW_MARGIN + (PREVIEW_COLS * (GENERATE_SQUARE+PREVIEW_MARGIN)), 3), 255, dtype=np.uint8) generated_images = generator.predict(noise) generated_images = 0.5 * generated_images + 0.5 image_count = 0 for row in range(PREVIEW_ROWS): for col in range(PREVIEW_COLS): r = row * (GENERATE_SQUARE+16) + PREVIEW_MARGIN c = col * (GENERATE_SQUARE+16) + PREVIEW_MARGIN image_array[r:r+GENERATE_SQUARE,c:c+GENERATE_SQUARE] = generated_images[image_count] * 255 image_count += 1 output_path = os.path.join(DATA_PATH,'output') if not os.path.exists(output_path): os.makedirs(output_path) filename = os.path.join(output_path,f"train-{cnt}.png") im = Image.fromarray(image_array) im.save(filename)Creating Combined Model.
image_shape = (GENERATE_SQUARE,GENERATE_SQUARE,IMAGE_CHANNELS) optimizer = Adam(1.5e-4,0.5) # learning rate and momentum adjusted from paper discriminator = build_discriminator(image_shape) discriminator.compile(loss="binary_crossentropy",optimizer=optimizer,metrics=["accuracy"]) generator = build_generator(SEED_SIZE,IMAGE_CHANNELS) random_input = Input(shape=(SEED_SIZE,)) generated_image = generator(random_input) discriminator.trainable = False validity = discriminator(generated_image)Training and Generating the Images:
y_real = np.ones((BATCH_SIZE,1)) y_fake = np.zeros((BATCH_SIZE,1)) fixed_seed = np.random.normal(0, 1, (PREVIEW_ROWS * PREVIEW_COLS, SEED_SIZE)) cnt = 1 for epoch in range(EPOCHS): idx = np.random.randint(0,training_data.shape[0],BATCH_SIZE) x_real = training_data[idx] # Generate some images seed = np.random.normal(0,1,(BATCH_SIZE,SEED_SIZE)) x_fake = generator.predict(seed) # Train discriminator on real and fake discriminator_metric_real = discriminator.train_on_batch(x_real,y_real) discriminator_metric_generated = discriminator.train_on_batch(x_fake,y_fake) discriminator_metric = 0.5 * np.add(discriminator_metric_real,discriminator_metric_generated) # Train generator on Calculate losses generator_metric = combined.train_on_batch(seed,y_real) # Time for an update? if epoch % SAVE_FREQ == 0: save_images(cnt, fixed_seed) cnt += 1 print(f"Epoch {epoch}, Discriminator accuarcy: {discriminator_metric[1]}, Generator accuracy: {generator_metric[1]}") generator.save(os.path.join(DATA_PATH,"face_generator.h5"))