y = 1) and dog (y = 0). And x is the feature vector of the animals.y=0 y=1 ----------- x=1 | 1/2 0 x=2 | 1/4 1/4p(y|x) is
y=0 y=1
-----------
x=1 | 1 0
x=2 | 1/2 1/2
If you take a few minutes to stare at those two matrices, you will understand the difference between the two probability distributions.
The distribution p(y|x) is the natural distribution for classifying a given example x into a class y, which is why algorithms that model this directly are called discriminative algorithms.
Generative algorithms model p(x,y), which can be transformed into p(y|x) by applying Bayes rule and then used for classification.
However, the distribution p(x,y) can also be used for other purposes.
For example, you could use p(x,y) to generate likely (x,y) pairs.
From the description above, you might be thinking that generative models are more generally useful and therefore better, but it's not as simple as that.
This paper is a very popular reference on the subject of discriminative vs. generative classifiers, but it's pretty heavy going.
The overall gist is that discriminative models generally outperform generative models in classification tasks.
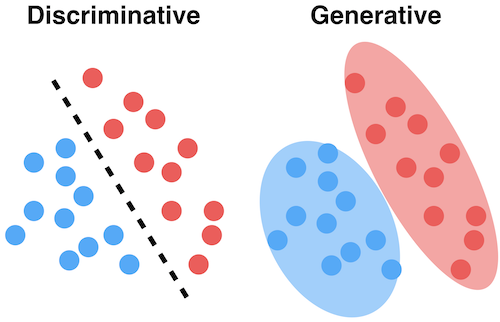
Generative models are models where the focus is the distribution of individual classes in a dataset and the learning algorithms tend to model the underlying patterns/distribution of the data points. These models use the intuition of joint probability in theory, creating instances where a given feature (x)/input and the desired output/label (y) exist at the same time.
Generative models use probability estimates and likelihood to model data points and distinguish between different class labels in a dataset. These models are capable of generating new data instances. However, they also have a major drawback. The presence of outliers affects these models to a significant extent.
Discriminative models, also called conditional models, tend to learn the boundary between classes/labels in a dataset. Unlike generative models, the goal here is to find the decision boundary separating one class from another.
So while a generative model will tend to model the joint probability of data points and is capable of creating new instances using probability estimates and maximum likelihood, discriminative models (just as in the literal meaning) separate classes by rather modeling the conditional probability and do not make any assumptions about the data point. They are also not capable of generating new data instances.
Discriminative models have the advantage of being more robust to outliers, unlike the generative models.
However, one major drawback is a misclassification problem, i.e., wrongly classifying a data point.
Another key difference between these two types of models is that while a generative model focuses on explaining how the data was generated, a discriminative model focuses on predicting labels of the data.
Examples of discriminative models in machine learning are:
Imagine your task is to classify a speech to a language.
You can do it by either:
or
The first one is the generative approach and the second one is the discriminative approach.
Check this reference for more details: http://www.cedar.buffalo.edu/~srihari/CSE574/Discriminative-Generative.pdf.
A generative algorithm models how the data was generated in order to categorize a signal. It asks the question: based on my generation assumptions, which category is most likely to generate this signal?
A discriminative algorithm does not care about how the data was generated, it simply categorizes a given signal.









