Take a few hundred data cases and look at the mean and standard deviation of the activation values of your units. You want to be out of the saturation regime of the tanh sigmoid.
I doubt different reasonable initialization schemes will have much effect on the quality of your solutions. It is probably good enough to just initialize the weights to be uniform on the interval [-1/sqrt(N), +1/sqrt(N)], where N is the number of incoming connections.
That being said, what DOES tend to make a big difference is pretraining the network weights, either as an RBM or as an autoencoder. This can be helpful even for single hidden layer neural nets, although it is much more essential for deeper nets. You don't mention the architecture you are using, that information would allow a more helpful answer to your question.
There is even a new initialization rule that seems to work well described in this paper: http://www.iro.umontreal.ca/~lisa/publications2/index.php/publications/show/447 The paper also mentions some of the symptoms of bad initialization that I was alluding to above that you can easily check for.
To summarize, Uniform on [-1/sqrt(N), +1/sqrt(N)] isn't too bad nor is the one mentioned in the paper I link to. Don't worry about it too much if you use one of those. What is very important is pretraining the weights as an autoencoder (or Restricted Boltzmann Machine), which you should look in to even if you only have a single hidden layer.
If you want to pre-train the weights as an RBM, you could switch to logistic sigmoids and even initialize the weights from a small standard deviation Gaussian without running in to trouble.
The Sigmoid Function curve looks like a S-shape.

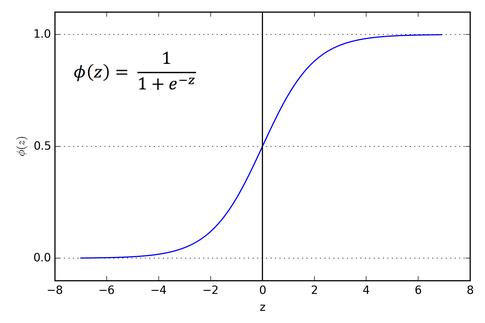 https://miro.medium.com/max/606/1*Xu7B5y9gp0iL5ooBj7LtWw.png 485w" alt="" width="485" height="323">
https://miro.medium.com/max/606/1*Xu7B5y9gp0iL5ooBj7LtWw.png 485w" alt="" width="485" height="323">The main reason why we use sigmoid function is because it exists between (0 to 1). Therefore, it is especially used for models where we have to predict the probability as an output.Since probability of anything exists only between the range of 0 and 1, sigmoid is the right choice.
The function is differentiable.That means, we can find the slope of the sigmoid curve at any two points.
The function is monotonic but function’s derivative is not.
The logistic sigmoid function can cause a neural network to get stuck at the training time.
The softmax function is a more generalized logistic activation function which is used for multiclass classification.
tanh is also like logistic sigmoid but better. The range of the tanh function is from (-1 to 1). tanh is also sigmoidal (s - shaped).

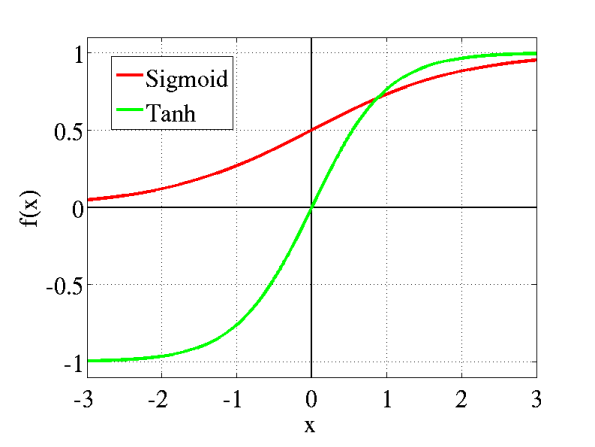 https://miro.medium.com/max/690/1*f9erByySVjTjohfFdNkJYQ.jpeg 552w, https://miro.medium.com/max/744/1*f9erByySVjTjohfFdNkJYQ.jpeg 595w" alt="" width="595" height="447">
https://miro.medium.com/max/690/1*f9erByySVjTjohfFdNkJYQ.jpeg 552w, https://miro.medium.com/max/744/1*f9erByySVjTjohfFdNkJYQ.jpeg 595w" alt="" width="595" height="447">The advantage is that the negative inputs will be mapped strongly negative and the zero inputs will be mapped near zero in the tanh graph.
The function is differentiable.
The function is monotonic while its derivative is not monotonic.
The tanh function is mainly used classification between two classes.
Both tanh and logistic sigmoid activation functions are used in feed-forward nets.
The ReLU is the most used activation function in the world right now.Since, it is used in almost all the convolutional neural networks or deep learning.

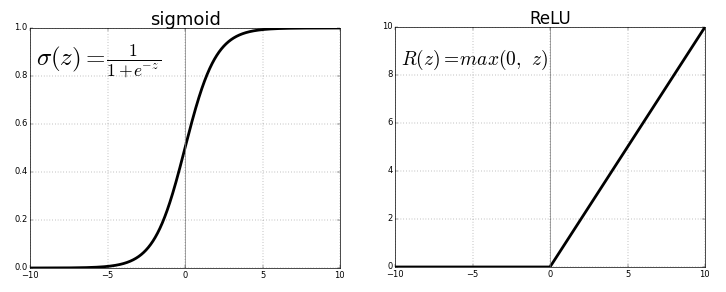 https://miro.medium.com/max/690/1*XxxiA0jJvPrHEJHD4z893g.png 552w, https://miro.medium.com/max/800/1*XxxiA0jJvPrHEJHD4z893g.png 640w, https://miro.medium.com/max/875/1*XxxiA0jJvPrHEJHD4z893g.png 700w" alt="" width="700" height="282">
https://miro.medium.com/max/690/1*XxxiA0jJvPrHEJHD4z893g.png 552w, https://miro.medium.com/max/800/1*XxxiA0jJvPrHEJHD4z893g.png 640w, https://miro.medium.com/max/875/1*XxxiA0jJvPrHEJHD4z893g.png 700w" alt="" width="700" height="282">As you can see, the ReLU is half rectified (from bottom). f(z) is zero when z is less than zero and f(z) is equal to z when z is above or equal to zero.
Range: [ 0 to infinity)
The function and its derivative both are monotonic.
But the issue is that all the negative values become zero immediately which decreases the ability of the model to fit or train from the data properly. That means any negative input given to the ReLU activation function turns the value into zero immediately in the graph, which in turns affects the resulting graph by not mapping the negative values appropriately.
It is an attempt to solve the dying ReLU problem
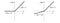
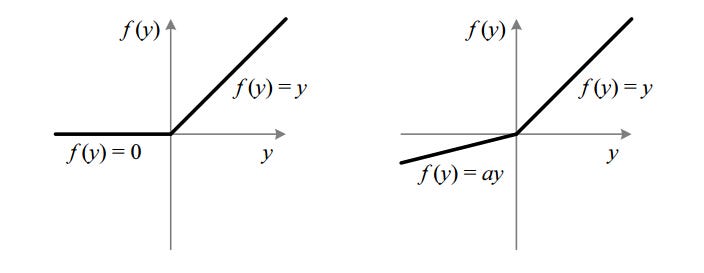 https://miro.medium.com/max/690/1*A_Bzn0CjUgOXtPCJKnKLqA.jpeg 552w, https://miro.medium.com/max/800/1*A_Bzn0CjUgOXtPCJKnKLqA.jpeg 640w, https://miro.medium.com/max/875/1*A_Bzn0CjUgOXtPCJKnKLqA.jpeg 700w" alt="" width="700" height="272">
https://miro.medium.com/max/690/1*A_Bzn0CjUgOXtPCJKnKLqA.jpeg 552w, https://miro.medium.com/max/800/1*A_Bzn0CjUgOXtPCJKnKLqA.jpeg 640w, https://miro.medium.com/max/875/1*A_Bzn0CjUgOXtPCJKnKLqA.jpeg 700w" alt="" width="700" height="272">The leak helps to increase the range of the ReLU function. Usually, the value of a is 0.01 or so.
When a is not 0.01 then it is called Randomized ReLU.
Therefore the range of the Leaky ReLU is (-infinity to infinity).
Both Leaky and Randomized ReLU functions are monotonic in nature. Also, their derivatives also monotonic in nature.








{kind=link}
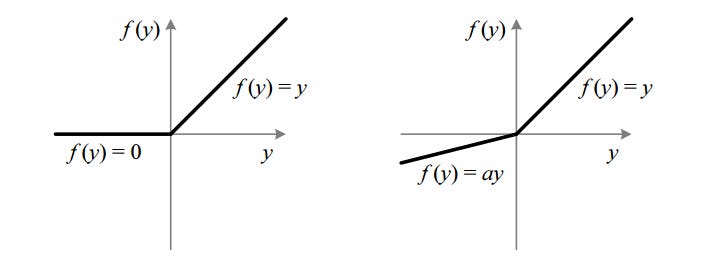{kind=link}