I trained quora question pair detection with LSTM but training accuracy is very low and always changes when i train. I dont understand what mistake i did.
I tried changing loss and optimiser and with increased epoch.
import numpy as np
from numpy import array
from keras.callbacks import ModelCheckpoint
import keras
from keras.optimizers import SGD
import tensorflow as tf
from sklearn import preprocessing
import xgboost as xgb
from keras import backend as K
from sklearn.preprocessing import OneHotEncoder, LabelEncoder
from keras.preprocessing.text import Tokenizer , text_to_word_sequence
from keras.preprocessing.sequence import pad_sequences
from keras.layers.embeddings import Embedding
from keras.models import Sequential, model_from_json, load_model
from keras.layers import LSTM, Dense, Input, concatenate, Concatenate, Activation, Flatten
from keras.models import Model
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer,CountVectorizer
import nltk
from nltk.stem.lancaster import LancasterStemmer
from nltk.tokenize import sent_tokenize, word_tokenize
from nltk.corpus import stopwords
import pandas as pd
import scipy
import matplotlib.pyplot as plt
import pickle
df = pd.read_csv("questions.csv")
df.drop(['id','qid1', 'qid2'], axis=1, inplace=True)
df2 = pd.read_csv("testmenew.csv") ## TO filter the dataset
SPECIAL_TOKENS = {
'quoted': 'quoted_item',
'non-ascii': 'non_ascii_word',
'undefined': 'something'
}
def clean(text, stem_words=True):
import re
from string import punctuation
from nltk.stem import SnowballStemmer
from nltk.corpus import stopwords
def pad_str(s):
return ' '+s+' '
if pd.isnull(text):
return ''
if type(text) != str or text=='':
return ''
text = re.sub("\'s", " ", text)
text = re.sub(" whats ", " what is ", text, flags=re.IGNORECASE)
text = re.sub("\'ve", " have ", text)
text = re.sub("can't", "can not", text)
text = re.sub("n't", " not ", text)
text = re.sub("i'm", "i am", text, flags=re.IGNORECASE)
text = re.sub("\'re", " are ", text)
text = re.sub("\'d", " would ", text)
text = re.sub("\'ll", " will ", text)
text = re.sub("e\.g\.", " eg ", text, flags=re.IGNORECASE)
text = re.sub("b\.g\.", " bg ", text, flags=re.IGNORECASE)
text = re.sub("(\d+)(kK)", " \g<1>000 ", text)
text = re.sub("e-mail", " email ", text, flags=re.IGNORECASE)
text = re.sub("(the[\s]+|The[\s]+)?U\.S\.A\.", " America ", text, flags=re.IGNORECASE)
text = re.sub("(the[\s]+|The[\s]+)?United State(s)?", " America ", text, flags=re.IGNORECASE)
text = re.sub("\(s\)", " ", text, flags=re.IGNORECASE)
text = re.sub("[c-fC-F]\:\/", " disk ", text)
text = re.sub('(?<=[0-9])\,(?=[0-9])', "", text)
text = re.sub('\$', " dollar ", text)
text = re.sub('\%', " percent ", text)
text = re.sub('\&', " and ", text)
text = re.sub('[^\x00-\x7F]+', pad_str(SPECIAL_TOKENS['non-ascii']), text)
text = re.sub("(?<=[0-9])rs ", " rs ", text, flags=re.IGNORECASE)
text = re.sub(" rs(?=[0-9])", " rs ", text, flags=re.IGNORECASE)
text = re.sub(r" (the[\s]+|The[\s]+)?US(A)? ", " America ", text)
text = re.sub(r" UK ", " England ", text, flags=re.IGNORECASE)
text = re.sub(r" india ", " India ", text)
text = re.sub(r" switzerland ", " Switzerland ", text)
text = re.sub(r" china ", " China ", text)
text = re.sub(r" chinese ", " Chinese ", text)
text = re.sub(r" imrovement ", " improvement ", text, flags=re.IGNORECASE)
text = re.sub(r" intially ", " initially ", text, flags=re.IGNORECASE)
text = re.sub(r" quora ", " Quora ", text, flags=re.IGNORECASE)
text = re.sub(r" dms ", " direct messages ", text, flags=re.IGNORECASE)
text = re.sub(r" demonitization ", " demonetization ", text, flags=re.IGNORECASE)
text = re.sub(r" actived ", " active ", text, flags=re.IGNORECASE)
text = re.sub(r" kms ", " kilometers ", text, flags=re.IGNORECASE)
text = re.sub(r" cs ", " computer science ", text, flags=re.IGNORECASE)
text = re.sub(r" upvote", " up vote", text, flags=re.IGNORECASE)
text = re.sub(r" iPhone ", " phone ", text, flags=re.IGNORECASE)
text = re.sub(r" \0rs ", " rs ", text, flags=re.IGNORECASE)
text = re.sub(r" calender ", " calendar ", text, flags=re.IGNORECASE)
text = re.sub(r" ios ", " operating system ", text, flags=re.IGNORECASE)
text = re.sub(r" gps ", " GPS ", text, flags=re.IGNORECASE)
text = re.sub(r" gst ", " GST ", text, flags=re.IGNORECASE)
text = re.sub(r" programing ", " programming ", text, flags=re.IGNORECASE)
text = re.sub(r" bestfriend ", " best friend ", text, flags=re.IGNORECASE)
text = re.sub(r" dna ", " DNA ", text, flags=re.IGNORECASE)
text = re.sub(r" III ", " 3 ", text)
text = re.sub(r" banglore ", " Banglore ", text, flags=re.IGNORECASE)
text = re.sub(r" J K ", " JK ", text, flags=re.IGNORECASE)
text = re.sub(r" J\.K\. ", " JK ", text, flags=re.IGNORECASE)
text = re.sub('[0-9]+\.[0-9]+', " 87 ", text)
text = ''.join([c for c in text if c not in punctuation]).lower()
return text
text = re.sub('(?<=[0-9])\,(?=[0-9])', "", text)
df['question1'] = df['question1'].apply(clean)
df['question2'] = df['question2'].apply(clean)
df2['q1'] = df2['q1'].apply(clean)
df2['q2'] = df2['q2'].apply(clean)
main =df['is_duplicate'].values
main.shape
(404351,)
vocabularySize = 2000
lstm_out = 200
embed_dim = 128
Rawdata=df['question1'].apply(word_tokenize)
Rawdata2=df['question2'].apply(word_tokenize)
testme = df2['q1'].apply(word_tokenize)
testme2=df2['q2'].apply(word_tokenize)
tokenizer2 = Tokenizer(num_words = vocabularySize )
tokenizer2.fit_on_texts(testme)
tokenizer2.fit_on_texts(testme2)
tokenizer = Tokenizer(num_words = vocabularySize )
tokenizer.fit_on_texts(Rawdata)
tokenizer.fit_on_texts(Rawdata2)
sequences = tokenizer.texts_to_sequences(Rawdata)
sequences2 = tokenizer.texts_to_sequences(Rawdata2)
sequences3 = tokenizer2.texts_to_sequences(testme)
sequences4 = tokenizer2.texts_to_sequences(testme2)
data = pad_sequences(sequences, maxlen=2)
data2 = pad_sequences(sequences2, maxlen=2)
data3 = pad_sequences(sequences3, maxlen=2)
data4 = pad_sequences(sequences4, maxlen=2)
TestInput = np.array([data3,data4])
TestInput = TestInput.reshape(1,2,2)
Input = np.array([data,data2])
Input = Input.reshape(404351,2,2)
#opt = SGD(lr = 0.001, momentum = 0.60)
model = Sequential()
#model.add(Embedding(1, 4,input_length = 2 , dropout = 0.4))
model.add(LSTM((1), input_shape = (2,2), return_sequences=False))
model.add(Activation ('sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adagrad', metrics=['accuracy'])
X_train,X_test,y_train,y_test = train_test_split(Input,main,test_size = 0.2,random_state = 4)
Input.shape
(404351, 2, 2)
history = model.fit(X_train,y_train,epochs = 10,validation_data= (X_test,y_test) )
model.save_weights('newoutput2.h5')
Train on 323480 samples, validate on 80871 samples Epoch 1/10 323480/323480 [==============================] - 27s 83us/step - loss: 0.6931 - acc: 0.6304 - val_loss: 0.6931 - val_acc: 0.6323 Epoch 2/10 323480/323480 [==============================] - 24s 73us/step - loss: 0.6931 - acc: 0.6304 - val_loss: 0.6931 - val_acc: 0.6323 Epoch 3/10 323480/323480 [==============================] - 23s 71us/step - loss: 0.6931 - acc: 0.6304 - val_loss: 0.6931 - val_acc: 0.6323 Epoch 4/10 323480/323480 [==============================] - 23s 71us/step - loss: 0.6931 - acc: 0.6304 - val_loss: 0.6931 - val_acc: 0.6323 Epoch 5/10 323480/323480 [==============================] - 23s 72us/step - loss: 0.6931 - acc: 0.6304 - val_loss: 0.6931 - val_acc: 0.6323 Epoch 6/10 323480/323480 [==============================] - 23s 71us/step - loss: 0.6931 - acc: 0.6304 - val_loss: 0.6931 - val_acc: 0.6323 Epoch 7/10 323480/323480 [==============================] - 23s 71us/step - loss: 0.6931 - acc: 0.6304 - val_loss: 0.6931 - val_acc: 0.6323 Epoch 8/10 323480/323480 [==============================] - 25s 76us/step - loss: 0.6931 - acc: 0.6304 - val_loss: 0.6931 - val_acc: 0.6323 Epoch 9/10 323480/323480 [==============================] - 25s 78us/step - loss: 0.6931 - acc: 0.6304 - val_loss: 0.6931 - val_acc: 0.6323 Epoch 10/10 323480/323480 [==============================] - 25s 78us/step - loss: 0.6931 - acc: 0.6304 - val_loss: 0.6931 - val_acc: 0.6323
filename = 'newoutput2.h5'
model.load_weights(filename)
new = model.predict(TestInput)
if new > 0.3:
print("Duplication detected")
else:
print("No duplicate")
new
giving output around 0.6567 but not atall increasing, Please help !!There are 4 ways to improve deep learning performance:
Improve Performance With Data:
Improve Performance With Algorithms
Improve Performance With Algorithm Tuning
some ideas on tuning your neural network algorithms in order to get more out of them.
Improve Performance With Ensembles
three general areas of ensembles you may want to consider:
check below link for further information: https://machinelearningmastery.com/improve-deep-learning-performance/
Having more data is always a good idea. It allows the “data to tell for itself,” instead of relying on assumptions and weak correlations. Presence of more data results in better and accurate models.
I understand, we don’t get an option to add more data. For example: we do not get a choice to increase the size of training data in data science competitions. But while working on a company project, I suggest you to ask for more data, if possible. This will reduce your pain of working on limited data sets.
The unwanted presence of missing and outlier values in the training data often reduces the accuracy of a model or leads to a biased model. It leads to inaccurate predictions. This is because we don’t analyse the behavior and relationship with other variables correctly. So, it is important to treat missing and outlier values well.
Look at the below snapshot carefully. It shows that, in presence of missing values, the chances of playing cricket by females is similar as males. But, if you look at the second table (after treatment of missing values based on salutation of name, “Miss” ), we can see that females have higher chances of playing cricket compared to males.
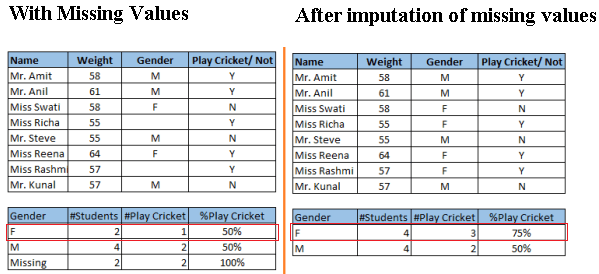 https://www.analyticsvidhya.com/wp-content/uploads/2015/12/Data_Exploration_2_11-300x137.png 300w" alt="Data_Exploration_2_11" width="599" height="274">
https://www.analyticsvidhya.com/wp-content/uploads/2015/12/Data_Exploration_2_11-300x137.png 300w" alt="Data_Exploration_2_11" width="599" height="274">
Above, we saw the adverse effect of missing values on the accuracy of a model. Gladly, we have various methods to deal with missing and outlier values:
This step helps to extract more information from existing data. New information is extracted in terms of new features. These features may have a higher ability to explain the variance in the training data. Thus, giving improved model accuracy.
Feature engineering is highly influenced by hypotheses generation. Good hypothesis result in good features. That’s why, I always suggest to invest quality time in hypothesis generation. Feature engineering process can be divided into two steps:
Feature Selection is a process of finding out the best subset of attributes which better explains the relationship of independent variables with target variable.

You can select the useful features based on various metrics like:
 https://www.analyticsvidhya.com/wp-content/uploads/2015/12/box-plot-300x213.png 300w" alt="box-plot" width="319" height="226">
https://www.analyticsvidhya.com/wp-content/uploads/2015/12/box-plot-300x213.png 300w" alt="box-plot" width="319" height="226">
Add more lstm layers and increase no of epochs or batch size see the accuracy results. You can add regularizers and/or dropout to decrease the learning capacity of your model. may some adding more epochs also leads to overfitting the model ,due to this testing accuracy will be decreased.
be balanced on no of epochs and batch size .







